

赛道通知:www.aicomp.cn/notice/notice-3/4275.html
一、赛题背景
煤气是钢铁企业高炉、焦炉、转炉生产过程中的主要副产能源。这些煤气经回收净化后,可直接送入燃气锅炉和发电机组进行自发电,即企业利用副产煤气自己发电,从而减少从电网购电。与余热、光伏等其他自发电形式不同,煤气自发电的燃料来源于生产节奏不稳定的冶炼过程,其发生量波动大、可存储性差,只能依靠气柜进行短期缓冲,因此预测难度最高,也最直接地影响企业的整体用电成本。
煤气自发电的预测精度对企业购电策略至关重要。大多数钢铁企业参与电力现货市场交易,企业需要在今天根据次日预测的自发电量以及生产过程计划用电量,决定从电网购买多少电量。如果买少了,高峰时段就必须以高价临时补电;如果买多了,低价时段购入的多余电力既无法存储,也无法按购入价回售,造成成本浪费。更关键的是,企业向电网申报的最大需量直接决定了每月的基本电费支出。如果自发电量预测值偏小,实际自发电不足会导致企业从电网紧急取电,最大需量会飙升,次月电费剧增;如果预测值偏大,企业虚占需量容量同样造成浪费。煤气自发电量预测的精度直接决定了企业购电计划的合理性与经济性,预测误差直接影响月度成本波动。因此,高精度的煤气自发电量预测是企业降本增效的核心前提之一。
然而,仅做发电量预测远远不够。在实际生产中,发电调度并非“能发多少就发多少”,而是必须在多种约束下制定发电计划。第一是气柜容量约束:煤气柜有安全上下限,为保证储气用气安全,柜位过高会引发放散,既浪费能源又面临环保处罚;柜位过低则可能无法满足发电机组瞬时需求。第二是机组出力特性:燃气机组有最小稳定负荷和爬坡速率限制,不可随意启停。第三是电价峰谷约束:江苏省将一天划分为尖、峰、平、谷时段,企业希望在电价高时多发自发电来替代外购电,在电价低时适当少发,利用低价电网电。
本赛题旨在挖掘面向能源降本增效的智能算法方案。参赛者需要利用历史数据建立高精度的煤气自发电量预测模型;再在满足生产约束的前提下,设计合理的发电计划优化策略,明确机组何时启停、负荷如何分配,最终实现企业能源运营收益最大化。
二 、赛题应用场景
本赛题的应用场景为钢铁企业能源调度中心。每日,调度员需完成以下工作:
- 根据次日生产计划(铁水产量、轧钢节奏等)和历史数据,预测次日各时段的煤气自发电量。
- 在气柜安全限值、机组爬坡约束、电价峰谷时段等条件下,制定未来24小时的发电机组启停计划和负荷分配方案。
- 将发电计划与企业购电策略联动,向电网申报次日最大需量和购电曲线。
目前多数企业依赖人工经验进行调度,预测误差大、计划保守。本赛题旨在通过数据驱动的智能算法,实现预测与优化一体化,显著提升能源经济性。
三、赛题任务
(一)任务描述
参赛者需要掌握时间序列分析方法,能够进行多源异构数据的预处理与特征工程,熟悉线性规划、整数规划或启发式算法,利用提供的多源时序数据(煤气产耗、气柜状态、机组负荷、电价时段),完成以下核心任务:
- 自发电量预测:构建高精度预测模型,输出未来一段时间的煤气产耗量及由此产生的发电机组负荷(即自发电量),评估指标为1-MAPE。该预测对象是指,按照企业历史运行方式,煤气产耗趋势下的发电量。短周期指2小时,长周期指24小时。
- 发电计划优化:基于预测结果获得的未来资源边界,在满足气柜容量、煤气用户需求等约束下,设计合理的发电机组调度策略(何时启停、负荷分配),以最大化峰谷电价收益。
- 两项任务顺序执行,先完成预测,获得未来资源约束(例如可用于发电的煤气量),再基于这些约束进行优化。
(二)任务输入输出说明
- 输入:历史数据文件,以及江苏省电价峰谷时段划分和电价数据。预测时仅允许使用参考时刻及其之前的数据,禁止未来信息泄露。
- 输出:对每个测试样本(时间点或时段),输出两个预测值:单台机组负荷(若有多台)和总发电负荷(具体以官方提交模板为准),以及输出一个未来一段时间的发电计划(各煤气量)。
四、数据集及数据说明
(一) 数据来源
数据来源于某钢铁企业高炉、焦炉、转炉生产过程中的真实业务记录,包括以下四类数据:
| 数据类型 | 描述 | 采样频率 |
| 高炉、焦炉、转炉的煤气发生量与消耗量 | 各炉煤气实时产耗数据 | 1分钟~15分钟 |
| 煤气柜数据 | 高炉煤气、焦炉煤气、转炉煤气的气柜流量、容量和压力 | 1分钟~15分钟 |
| 发电机组负荷 | 发电机组实时负荷数据 | 1分钟~15分钟 |
| 江苏省电价峰谷时段划分和电价 | 电价时段划分说明 | – |
原始基础数据经主办方进行匿名化、脱敏化、字段标准化和格式转换后,以赛事专用数据包形式提供。
(二) 数据规模
本赛题所有样本时间范围覆盖2025年1月1日至2025年10月31日,均为分钟级生产数据。
本赛题采用时间顺序切分方式组织数据,以贴近工业场景实际部署方式并避免时间穿越。赛事按阶段逐步释放数据,各阶段所释放的数据均可自由组合用于模型迭代与训练。数据集划分如下:
初赛阶段:2025年1月1日 至 2025年4月30日(约4个月,涵盖冬春交替工况)。评测数据(指用于评分、选拔等):2025年5月1日 至 2025年5月2日。
复赛阶段: 2025年5月3日 至 2025年7月31日数据(约3个月,涵盖夏季高负荷工况)。评测数据:2025年8月1日 至 2025年8月5日。
半决赛阶段: 2025年8月6日 至 2025年9月30日数据(约2个月,涵盖夏秋交替工况)。评测数据:2025年10月1日 至 2025年10月10日。
决赛阶段:测评数据2025年10月11日 至 2025年10月31日数据。
时间序列数据文件格式为CSV(逗号分隔值),编码为 UTF-8, 所有时间序列数据的时间戳格式统一为 YYYY-MM-DD HH:MM:SS。
数据集包含以下文件:
| 文件名称 | 数据粒度 | 主要说明 |
| gas.csv | 分钟级 | 包含高炉、焦炉、转炉煤气的发生量和消耗量等字段。 |
| gas_holder.csv | 分钟级 | 包含高炉、焦炉、转炉煤气气柜容量等字段。 |
| gas_user.csv | 分钟级 | 包含高炉、焦炉、转炉煤气用户的消耗量等字段。 |
| load.csv | 分钟级 | 包含发电负荷等字段。 |
| 江苏省电价峰谷时段 | – | 江苏省1月至12月电价时段划参考数据 |
| data_dictionary.xlsx | 说明文件 | 字段释义、单位说明及使用事项 |
(三)数据字段说明
企业拥有多座高炉、焦炉和转炉,且煤气用户较多,为了便于参赛者快速理解数据,将以数字编号命名,数字编号不区分先后和用户优先级,例如“blast_furnace_1”表示1号高炉,“blast_furnace_user1”表示高炉煤气用户1。
| 文件名称 | 参数 | 数据说明 |
| gas.csv | blast_furnace_1 | 1号高炉煤气发生量。 |
| air_heater_1
|
1号热风炉的高炉煤气消耗量。热风炉作为高炉冶炼的重要附属设备,为高炉冶炼提供热量,但与此同时也消耗了高炉煤气。热风炉编号与高炉编号一一对应,例如1号热风炉只会消耗1号高炉生产的煤气。 | |
| coke_oven_1 | 1号焦炉煤气发生量。 | |
| converter_1 | 1号转炉煤气发生量。 | |
| into_gas_mixed_blast_furnace | 进混气站的高炉煤气量。 | |
| into_gas_mixed_coke | 进混气站的焦炉煤气量。 | |
| into_gas_mixed_converter | 进混气站的转炉煤气量。 | |
| gas_holder.csv | blast_furnace_gas_holder_1 | 1号高炉气柜。气柜的作用是存储高炉煤气和稳定管网压力,可存储多个高炉的煤气。 |
| gas_user.csv | blast_furnace_user1
|
高炉煤气用户1。消耗高炉煤气,需要优先供应高炉煤气,以保证正常生产。 |
| converter_user1 | 转炉煤气用户1。消耗转炉煤气,掺烧转气的目的是保证生产排放达标。 | |
| mixed_gas_user1 | 混气用户1。除了直接使用煤气的用户外,还有些用户需要使用混合煤气(高炉、焦炉、转炉煤气混合),需要优先供应混合煤气,以保证正常生产。 | |
| load.csv | generator_1 | 发电机组1。 |
| generator_all | 全部发电机组。6套机组总负荷,包含4套50MW和2套120MW发电机组。 | |
| generator_use_coke_gas | 发电机组消耗的焦炉煤气量。 | |
| generator_use_converter_gas | 发电机组消耗的转炉煤气量。 | |
| generator_use_blast_furnace_gas | 发电机组消耗的高炉煤气量。 | |
| price.xlsx | – | 一年每月分时电价,列名为1月至12月。电价会随市场变化,该数据仅供本赛题使用。 |
(四)数据预处理说明
原始数据已经过脱敏和基础格式统一(时间戳格式 YYYY-MM-DD HH:MM:SS,编码 UTF-8),但仍可能存在缺失值、重复值、异常值。参赛者需自行完成多表时序对齐、缺失处理、异常检测等清洗工作。
五、算法设计要求
(一)模型类型
本赛题禁止使用任何闭源和商用大模型(包括但不限于 GPT-4、Claude、Gemini、文心一言商业版等),鼓励参赛者采用适合工业时序数据的机器学习或深度学习方法,包括但不限于XGBoost、LightGBM、随机森林、多层感知机、Transformer等。
(二)创新性
本鼓励参赛者围绕多表时序对齐、工业机理先验注入、异常样本鲁棒性处理、多目标协同建模、可解释性分析等方向形成创新方案。
六、性能指标要求
本赛题聚焦煤气发电量预测。针对高精度和高响应的业务需求,本赛题采用1-平均绝对百分比误差(MAPE)作为评估参赛模型性能的核心指标,其中MAPE的计算公式为:
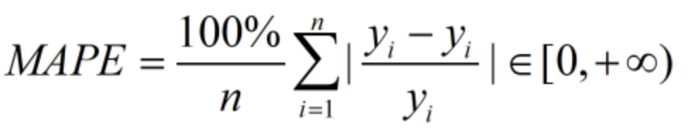
参赛者的算法模型必须在保证基础准确率的前提下,尽可能保证响应速度。
本赛题同时也聚焦煤气发电优化。针对发电计划优化,本赛题采用约束满足性、电价时段利用效率和经济效益提升三个指标作为评估参赛模型的核心指标。其中,各指标的定义如下:
- 约束满足性
本场景的气柜容量为20万m³,为了保证生产安全,气柜的柜位(柜容)全程保持在安全区间内,低柜位(下限)约为15%柜容,高柜位(上限)约为90%柜容,高高柜位约为95%柜容;煤气用户无供气不足的时段。发电机组有装机容量,正常运行下发电负荷在60%至100%间,场景中的发电机组为4套50MW和2套120MW发电机组,其中generator_1指的是4套50MW机组的负荷,generator_all指的是6套机组总负荷。本赛题中,将机组的爬坡速率设定为10%额定容量/分钟。
- 电价时段利用效率
电价加权负荷比的计算公式为:
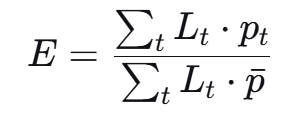
其中为t时刻计划发电负荷,为t时刻电价(尖峰平谷对应不同单价),为全天平均电价。
- 经济效益提升
将发电计划与历史发电进行经济效益对比,收益计算包括替代外购电效益(自发电每度替代外购电一度)和煤气放散惩罚,计算相对收益提升率:
相对收益提升率 = (优化效益 – 基准效益)/基准效益
七、功能要求
- 可靠性
面对不同月份和不同节奏区间的样本,算法应保持稳定输出,不应因局部工况变化出现成批失真。
- 鲁棒性
算法应对缺失值、重复值、异常值、统计口径差异和明细级多行聚合问题具备较强鲁棒性。
- 时效性
在统一测评环境中,算法应在规定时间内完成全量测试样本推理。原则上,单样本平均推理耗时不超过 30 秒,全量阶段测试集推理时长不超过 30 分钟;正式阈值以赛事发布稿和测评细则为准。
- 可解释性
鼓励参赛者提供特征重要性分析、样本级误差分析或关键影响因素可视化,以增强结果可解释性。
- 功能测试方式
赛事方将在统一离线环境中测试算法是否能够正确读取数据、按要求生成结果文件,并检查结果完整性、字段合法性、样本覆盖率、运行时长和可复现性。
- 优化调度
输出未来一段时间的发电计划。
八、开发环境
(一)软件环境
操作系统:Linux(推荐 Ubuntu 20.04/22.04)或 Windows 10/11。
编程语言:Python 3.8 – Python 3.10。
推荐依赖:NumPy、Pandas、SciPy、scikit-learn、XGBoost、LightGBM、CatBoost、PyTorch、Matplotlib、Seaborn。
工程文件:应提供 requirements.txt、README.md、运行脚本等辅助文件。
(二)硬件环境
CPU 环境:8 核及以上 CPU,32GB 及以上内存。
GPU 环境:非强制要求;若采用深度学习方案,建议单卡显存 16GB 及以上。
存储空间:建议可用磁盘空间 50GB 及以上。
九、成绩评价
(一)指标权重
本赛题的成绩评价贯穿初赛、复赛、半决赛和总决赛四个阶段。为了全面衡量算法在复杂工况下的稳定表现,将采用机器评分为主的评分方式。
- 初赛阶段
数据校验与预处理权重为50%,短周期预测指标权重为50%。主要用于参赛者熟悉能源预测场景,掌握基本数据处理和回归预测方法。依据初赛数据集综合机器评分进行排序。初赛阶段的测评得分仅适用于初赛,用于开发验证和晋级选拔。
- 复赛与半决赛阶段
短周期预测指标权重为50%,长周期预测指标权重为50%。依据复赛和半决赛数据集总和机器评分排序,作为总决赛的客观评分基础。
- 决赛阶段
总决赛采用“70% 客观评分 + 30% 主观评分”的评价方式。其中客观评分为复赛机器测评得分标准化结果,主观评分由专家组结合技术创新性、工业可落地性、结果复现性、技术文档质量和答辩表现综合给出。
(1)客观评分(机器测评)(权重:70%):以测试集综合机器评分标准化结果计入。
(2)技术创新性(权重:10%):主要考察特征设计、模型方法和问题解决思路。
(3)工程复现性(权重:10%):主要考察代码运行、结果复现、效率和提交规范性。
(4)技术文档与答辩质量(权重:10%):主要考察文档完整性、表达逻辑、分析深度和答辩表现。
- 有效成绩阈值
机器评分不低于60分,且不低于官方基线参考分数。
(二)评分细则
- 数据一致性校验:包含多源数据时间对齐、单位统一、采样频率统一。
- 数据预处理:包含数据完整性达标、异常值检测与修正、重复数据剔除、时间连续性处理、去噪、清洗流程与可复现。
- 数据预测:短周期指2小时,长周期指24小时。
- 发电优化:与预测周期保持一致;包含用于发电的煤气量。
十、解题思路
(一)知识点
本赛题主要考核工业多表数据理解、时间序列对齐、特征工程、回归建模、多模板优化、异常处理、时间切分验证、结果解释与工程复现等知识点。
(二)思路引导
- 明确数据粒度,统一数据采样频率,建议统一至15分钟/次,并完成多个数据的时序对齐;
- 可通过特征工程构造符合业务规则的新特征,增强模型的学习能力;
- 发电机组基于煤气可用量进行发电,在预测未来发电量时,可先对煤气可用量进行预测。煤气可用量等于煤气发生量与消耗量之差,其中消耗量包括生产用户消耗量;
- 建议采用时间顺序切分进行验证,避免随机切分造成未来信息泄露;
- 建议采用滚动预测,保持输入和输出窗口长度;
- 对于大偏差样本进行分析,识别异常工况;
- 煤气发电计划优化的核心是优先保正常生产,其次才是降本。正常生产包括:煤气用户能够保证正常生产、气柜压力稳定(通过柜容进行判断)。此外,应尽量避免煤气放散。
(三)注意事项
- 严禁在特征构建或验证中使用参考时刻之后的数据;
- 若采用深度学习方案,应注意不同字段量纲带来的归一化问题;
- 结果文件中,预测结果不得缺失或错位。如果有发电优化方案,计划内容不得超越生产约束。
十一、赛题约束条件
(一)算法约束
- 禁止使用任何商业闭源在线推理接口或需要联网调用的模型服务;
- 禁止通过人工逐条修正测试结果;
- 禁止使用未来信息、测试标签泄露信息或通过测试集反推标签;
- 进入总决赛的方案须支持离线环境完整运行。
(二)数据使用约束
- 参赛者仅可使用赛事官方提供的数据,严禁使用任何外部公开数据、私有数据或自行采集数据;
- 严禁使用依赖外部数据训练得到的预训练模型权重;允许使用开源算法框架、开源代码库和通用基础依赖库,但不得借助外部数据增强模型能力;
- 禁止传播、转售、公开展示、用于商业用途或泄露赛事数据;
- 所有数据仅授权用于本赛事相关算法研究与评测。
十二、参考资源
(一)文献资料
- 何相君, 雷婧, 彭宝祥, 等.钢铁副产煤气资源化利用技术及效益分析[J/OL].现代化工, 1-7[2026-04-25].https://link.cnki.net/urlid/11.2172.TQ.20260420.1511.034.
- 刘书含, 孙文强.“数智赋能”背景下钢铁企业副产煤气产耗量预测[C]//中国金属学会能源与热工分会, 东北大学.第十三届全国能源与热工学术年会论文(摘要)集.东北大学冶金学院; 2025:135136.DOI:10.26914/c.cnkihy.2025.052288.
- XGBoost: A Scalable Tree Boosting System. KDD 2016.
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree. NeurIPS 2017.
- CatBoost: unbiased boosting with categorical features. NeurIPS 2018.
(二)在线资源
【第九讲–常见的四种煤气发电工艺】
https://www.bilibili.com/video/BV1fHUpBjEx6/?share_source=copy_web&vd_source=752a33c4774ca9d112c09c887e443e08
十三、提交要求
(一)初赛提交内容
参赛者需完成滚动预测,将预测结果保存为csv文件,其中预测模型的输入为input.csv,短周期预测为s_result.csv,编码为 UTF-8,并压缩为zip文件后提交。
结果文件字段要求如下:
- datetime(字符串):时间戳格式统一为 YYYY-MM-DD HH:MM:SS。
- csv(浮点型):参赛者构建的预测模型的输入变量,包含datetime、原始特征和特征工程构造的特征。原始特征字段名称须与赛事要求完全一致,特征工程构造的特征(如有)的字段名称需包含前缀“feat_”。
- csv:必须包含datetime,以及generator_1和generator_all在不同预测步长下的预测值。datetime指滚动预测的起点时刻,其余列名(参数名)以目标时刻偏移量命名。例如,步长为15分钟时,列名应类似generator_1_t+15_pred, ……,generator_1_t+120_pred,表示在当前起点预测未来15分钟到120分钟的generator_1负荷;generator_all同理。预测结果不得缺行、重复,建议保留三位及以上小数,单位与原始数据保持一致。
因评测数据存在时间边界,后期滚动起点的预测目标将超出所提供的数据范围。参赛者只需基于已有历史数据正常输出预测值即可,按起点时间完整输出预测宽表,评分脚本会自动根据起点时刻与偏移量计算目标时刻,并提取真实值完成评分计算。此要求说明与复赛、半决赛、决赛相同,之后不再重复描述。
注:提交限制:每天最多提交 5 次,排行榜实时更新,以最后一次提交为准。
(二)复赛和半决赛提交内容
参赛者需完成滚动预测,将预测结果保存为csv文件,其中短周期预测结果为s_result.csv,长周期预测结果为l_result.csv,编码为 UTF-8,并压缩为zip文件后提交。
结果文件字段要求如下:
- datetime(字符串):时间戳格式统一为 YYYY-MM-DD HH:MM:SS。
- csv:必须包含datetime,以及generator_1和generator_all在不同预测步长下的预测值。datetime指滚动预测的起点时刻,其余列名(参数名)以目标时刻偏移量命名。例如,对于步长为15分钟,列名应类似generator_1_t+15_pred, ……,generator_1_t+120_pred,表示在当前起点预测未来15分钟到120分钟的generator_1负荷;generator_all同理. 预测结果不得缺行、重复,建议保留三位及以上小数,单位与原始数据保持一致。
- csv:必须包含datetime,以及generator_1和generator_all在不同预测步长下的预测值。datetime指滚动预测的起点时刻,其余列名(参数名)以目标时刻偏移量命名,要求同s_result.csv,即当设定步长为15分钟时,列名应类似generator_1_t+15_pred, ……,generator_1_t+1440_pred,表示当前器未来15分钟到24小时的generator_1负荷,generator_all同理. 预测结果不得缺行、重复,建议保留三位及以上小数,单位与原始数据保持一致。
(三)决赛提交内容
- 算法代码:包含数据读取、预处理、特征构建、模型训练、预测推理与优化等完整代码。
- 模型文件:训练好的模型参数文件。
- 技术报告:PDF或Word格式。
- README文件:说明运行环节、依赖安装、运行命令和输入输出目录结构。
- s_result.csv:短周期预测结果,单位与原始数据保持一致。
- l_result.csv:长周期预测结果,单位与原始数据保持一致。
- opt_result.csv:优化结果。优化结果包含发电用的高炉、焦炉、转炉煤气字段的浮点型数据,字段需包含前缀“opt_”,单位与原始数据保持一致。
CSV 文件应使用 UTF-8 编码,字段名称须与赛事要求完全一致;每个样本编号只能出现一次;不得缺行、重复或附加多余字段。预测对象必须包含煤气发电量(发电机组负荷),煤气发生量和消耗量作为可选对象。优化对象必须包含用于发电的高炉、焦炉、转炉煤气量,其余作为可选对象。预测值建议保留三位及以上小数。
如赛事组织方需要,可额外提交视频、答辩PPT和补充说明材料。
(四)提交规范
- 所有提交材料须保证可读取、可解压、可运行;
- 初赛和复赛提交的 ZIP 压缩包内须包含且仅包含一个结果文件,结果文件固定命名为 result.csv;
- 初赛压缩包命名规则为 teamname_gas_predict_prelim.zip,复赛压缩包命名规则为 teamname_gas_predict_final.zip;
- 若代码与结果无法复现,赛事方有权取消成绩或奖项;
- 最终解释权归赛事主办方所有。
十四、奖励设置
为了鼓励参赛选手参赛积极性,激发在复杂制造场景下的技术创新潜能,本赛题不仅设立了丰厚的现金奖励,更针对优秀的青年算法人才开辟了专属的职业发展绿色通道。具体激励设置如下:
(一)赛事奖金设置
本赛题将根据总决赛的最终综合成绩(含线上客观评测与线下答辩),对全国总决赛一等奖前六名参赛团队按照如下标准颁发奖金:
- 冠军奖:第1名,奖金8000元/每团队
- 亚军奖:第2-3名,奖金6500元/每团队
- 季军奖:第4-6名,奖金3000元/每团队
注:所有获奖的参赛团队将得到相应比赛奖金(奖金以人民币计算),奖金金额均为税前标准。奖金对应的个人所得税由获奖团队承担,由江苏省人工智能学会代扣代缴。税后奖金统一支付至获奖团队的队长账户。
(二) 人才招募专属特权
为加速“人工智能+”创新成果向新质生产力的转化,切实打通产学研用链路,针对在本赛题中展现出卓越代码能力与工程落地思维的优秀参赛选手(不限于前六名获奖团队成员),出题方还将额外提供以下极具含金量的职业发展激励:
- 核心岗位面试直通卡
在复赛或总决赛中表现突出的核心算法选手,将获得人工智能研究院算法研发岗位的“校招面试直通卡”。凭此卡可直接免除在线笔试与简历初筛环节,直通终审技术面,优先锁定高潜算法人才核心席位。
- 专项精英实习计划
定向开放工业计算机视觉、大模型前沿应用等核心研发方向的优质实习岗位。受邀实习生将直接参与真实的高级别产线视觉项目,享有充足的算力资源支持与资深算法研究员的1v1业务指导,积累宝贵的工业界实战经验,实习期间表现优异者可获全职Offer提前转正机会。
十五、其他说明
公平性:严禁任何形式的作弊行为,包括但不限于数据泄露、模型预训练数据与测试数据重叠、抄袭他人代码等。一经发现,立即取消参赛资格,并追究相关责任。
知识产权:参赛者提交的作品必须为原创,未在其他比赛中获奖或公开发表。比赛主办方有权对参赛作品进行展示、宣传等相关活动,但知识产权仍归参赛者所有。
十六、联系方式
赛题交流QQ群:1093810052
邮 箱:huanglinya@njsteel.com.cn
报名官网:www.aicomp.cn
赛题规则:煤气发电量预测与发电优化
 2025精彩瞬间
2025精彩瞬间
 大赛回顾
大赛回顾
 关注我们
关注我们