
赛道通知:www.aicomp.cn/tracks/tracks-1/3629.html
一、赛题背景
随着低空经济的蓬勃发展,无人机技术在测绘、安防、农业监测及城市规划等领域的应用日益广泛。无人机低空航拍图像具有视角独特、分辨率高、地物细节丰富等特点,但同时也面临着视角变化大、目标尺度差异显著、背景复杂等挑战。语义分割作为计算机视觉的核心任务之一,旨在对图像中的每个像素进行分类,是实现无人机视觉感知智能化的关键。
然而,现有的通用语义分割模型在直接应用于低空航拍场景时,往往因训练数据与航拍数据分布差异(DomainGap)而表现不佳。此外,航拍图像中不同地物类别(如农田、建筑、道路)的分布极不均衡,且测试场景中某些类别的占比可能与训练场景存在显著偏差(如特定区域农田占比过高),这要求模型具备极强的泛化能力和鲁棒性。本赛题希望通过开发高效的无人机低空航拍图像语义分割模型,探索在复杂分布数据环境下提升模型性能的方法,推动无人机视觉技术的落地应用。
二、赛题应用场景
无人机低空航拍图像语义分割技术是低空经济基础设施的重要组成部分,具有巨大的产业应用价值。
- 精准农业:通过分割农田、作物区域,监测作物长势及病虫害情况。
- 城市规划与测绘:自动提取建筑、道路、水体等信息,辅助地图更新与违建检测。
- 应急安防:在灾害现场快速识别道路通行情况、水体淹没区域及人员车辆分布。
- 环境保护:监测森林覆盖、荒地变化及水体污染情况。
参赛者通过解决本赛题,将能够深入了解低空视觉感知的挑战,为上述实际应用场景提供高精度的算法支持。
三、赛题任务
本赛题聚焦于无人机低空航拍图像的语义分割。参赛者需利用赛题方提供的训练数据集,训练高效的语义分割模型。赛事方提供的训练集来源于公开无人机数据及南航工信部重点实验室自采数据,已统一做了类别映射,并切分为1024*1024的patch。数据集中存在目标尺度差异大、数据跨域分布、类别分布不均衡等现实挑战(例如部分类别在测试集中占比显著高于训练集)。参赛者需充分利用训练数据,通过优化数据处理、模型架构、损失函数及训练策略等手段,提高模型在低空航拍场景下的分割精度。由于测试数据分三次发布,且存在类别、跨域分布特性差异,模型需具备优秀的泛化性,能够在不同的测试子集上均保持良好的识别性能。
四、数据集及数据说明
(一)数据来源
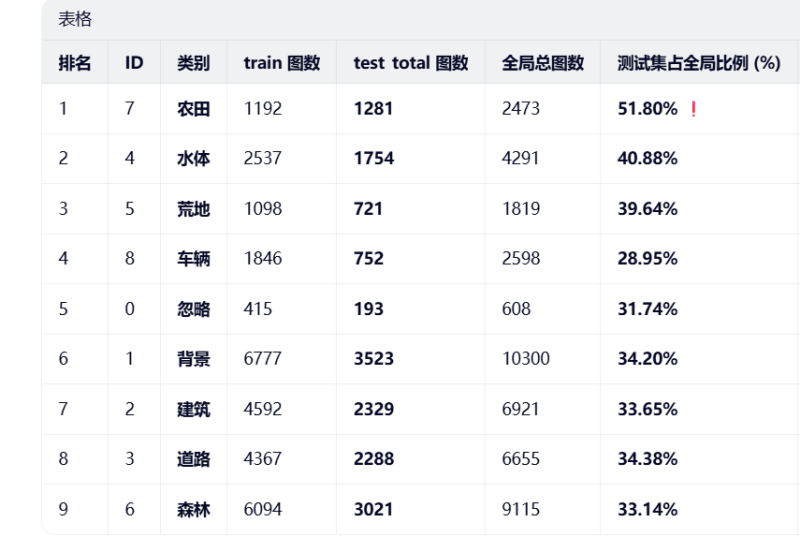
数据来源于公开无人机数据集(包含部分遥感图像)及南京航空航天大学工信部重点实验室自收集的无人机低空航拍数据。所有数据经过统一清洗、类别映射及预处理。训练、测试数据的整体信息如下表格:
(二)数据情况概要
- 图像规格:所有图像已统一切分为1024*1024像素的patch,并进行了重新排序。
- 类别体系:共包含9个语义类别(含背景及忽略类),具体包括:农田、水体、荒地、车辆、忽略、背景、建筑、道路、森林。每张图片会同时出现多个语义类别。
- 数据分布:训练集共6996张图像。测试集分为三次发布,测试集1含500张图像,将被用于为初赛测试数据;测试集2含1300张图像,将被用于为复赛测试数据;测试集3含1794张图像,将与测试集1、2合并,一起用于为半决赛测试数据。
- 分布特性:数据集存在显著的类别分布不均现象。统计显示,部分类别(如农田、水体)在测试集中的占比可能远高于训练集或全局平均水平,这对模型的类别平衡性提出了较高要求。例如,某些场景下超过一半的测试图片可能集中在特定地物类别上。
- 数据格式:训练数据将按照图像文件夹和标签文件夹的形式给出,标签图为单通道灰度图,像素值对应类别ID。
- 示例数据可从https://www.modelscope.cn/datasets/jmz001/Examples获取,正式数据将在报名后开放下载。
五、算法设计要求
鼓励参赛者提出创新性的深度学习算法或者改进现有算法,提升模型在低空航拍数据上的分割精度和鲁棒性。算法应具备良好的可扩展性,能够适应不同分辨率或不同场景的航拍数据。
竞赛过程中若使用预训练模型,只能采用学术领域权重公开的预训练模型做微调,不能使用商业闭源模型,不能使用额外数据。为鼓励算法创新,本次赛题不允许使用多模型集成(modelensemble),最终提交的结果应仅包含一个模型。复赛结束后,赛事方将对各参赛队伍提交的代码进行复现,若使用赛事方提供的数据集无法复现性能,将取消成绩。
六、性能指标要求
本竞赛性能得分以语义分割任务中普遍使用的平均交并比(mIoU,meanIntersectionoverUnion)作为评价指标。
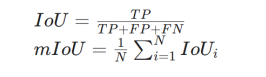
其中,N为类别数量(忽略类不参与计算),TP,FP,FN分别表示真阳性、假阳性和假阴性。本次竞赛对模型推理时间及模型大小不做限制,但需在合理范围内。
七、功能要求
参赛者需要设计创新性方法或改进现有算法,利用赛事方提供的训练集训练语义分割模型,最终在赛事方提供的测试数据集上表现出良好的准确性和鲁棒性。参赛者设计的方法需要在赛事方提供的不同测试子集上有良好的泛化性和通用性,能够有效应对数据分布偏移的问题。
八、开发环境
参赛者需要使用Python语言进行开发,可以使用开源的算法框架,如Pytorch等。
九、成绩评价
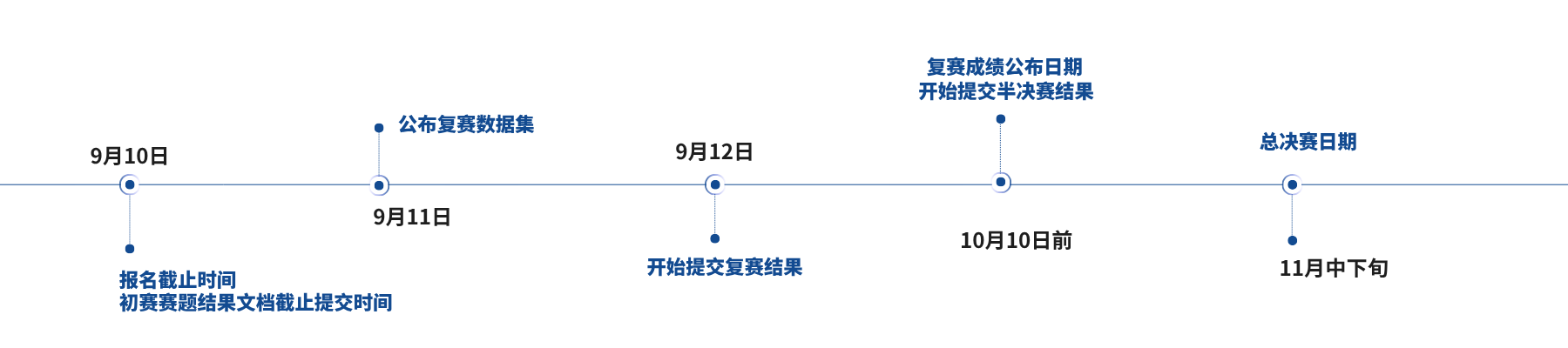
本赛题的赛事分为初赛、复赛、半决赛和总决赛四个阶段。
初赛:测试集1由机器自动评分(mIoU),但不计入决赛总分,算法性能得分取为算法在测试集1上的mIoU得分。仅用于参赛者前期算法验证与调试,具有有效成绩(mIOU>0)均可进入复赛。
复赛:测试集2由机器自动评分(mIoU),结果不计入决赛总分。算法性能得分取为算法在测试集2上的mIoU得分。
半决赛:测试集3,与测试集1、2合并为半决赛测试集,由机器自动评分(mIoU),结果计入决赛总分。
注:若参赛者提交结果低于赛事方公布的基线成绩,赛事方有权将其认定为无效成绩。
十、解题思路
本赛题数据源自多个数据集的混合,具有类别分布不均衡、域偏移显著、目标尺度差异大等特点。建议参赛团队从开源语义分割模型基线(如MMSegmentation、DeepLabV3+、SegFormer)入手,特别关注类别不平衡处理策略(如采用加权交叉熵损失、FocalLoss或DiceLoss等)优化少数类识别效果。同时关注域适应优化,建筑、农田等类别数据分布存在显著差异,建议引入数据增强(如色彩抖动、几何变换)或分布泛化技术提升模型泛化能力。此外,可关注多尺度特征融合,1024×1024图像包含不同尺度地物,可采用FPN、ASPP等结构增强多尺度特征表达能力。
十一、赛题约束条件
(一)算法约束
竞赛过程中若使用预训练(大)模型,只能采用学术领域权重公开的预训练模型做微调,不能使用商业闭源模型API。为鼓励算法创新,本次赛题不允许使用多模型集成(modelensemble),最终提交的结果应仅包含一个模型。半决赛结束后,赛事方将对各参赛队伍提交的代码进行复现,若使用赛事方提供的数据集无法复现性能,将取消成绩。
(二)数据使用约束
参赛者仅可使用赛事官方提供的数据集,不能使用额外数据。禁止参赛者将赛事提供的数据集泄露、传播或用于非赛事相关的商业用途,违反者取消参赛资格。
十二、参考资源
1.XieE,etal.”SegFormer:SimpleandEfficientDesignforSemanticSegmentationwithTransformers.”NeurIPS2021.
2. MMSegmentation开源库:https://github.com/open-mmlab/mmsegmentation
3.Sam3开源库:https://github.com/facebookresearch/sam3
十三、提交要求
(一)初赛提交内容及要求
参赛方需要在赛事方提供的初赛测试集(测试集1)上进行预测,并将预测结果保存为与输入图像文件名对应的标签图(PNG格式)。
注意事项:
请确保提交的预测文件命名与测试集中的文件名保持完全一致;
标签图的像素值需严格对应类别ID(0-8);
预测结果图必须保存为单通道PNG格式。严禁提交 RGB 彩色图、带调色板(Palette)的索引色 PNG 或其他非标准格式;
预测图的分辨率(宽×高,即尺寸)必须与对应的原始测试图像(均为1024×1024)严格保持一致;
评测系统将不对尺寸不匹配的文件进行自动缩放或裁剪处理。凡尺寸不一致、格式不符合要求的提交文件,将直接被判定为无效文件或错误预测,并计入零分处理;
最终将预测结果文件压缩为一个zip文件进行提交。
(二)复赛提交内容及要求
参赛选手需在官方提供的复赛测试集(测试集2)上进行预测,输出格式和初赛相同。最终将预测结果文件压缩为一个zip文件进行提交。
(三)半决赛提交内容及要求
- 参赛选手需在官方提供的半决赛测试集(测试集3和测试集1、2合并的数据集)上进行预测,输出格式和初赛相同。最终将预测结果文件压缩为一个zip文件进行提交。
- 可复现的docker文件,包含但不限于:
—完整的训练代码和验证代码,包括复现脚本。
—代码、环境、操作说明文档。
- 技术方案文件(PDF):要求包含算法设计动机,方法说明,伪代码等内容辅助证明所设计的方法的创新性和有效性。
(四)总决赛提交内容及要求
提交内容及具体要求以组委会后续正式通知为准。
十四、其他说明
公平性:严禁任何形式的作弊行为,包括但不限于数据泄露、模型预训练数据与测试数据重叠、抄袭他人代码等。一经发现,立即取消参赛资格,并追究相关责任。
知识产权:参赛者提交的作品必须为原创,未在其他比赛中获奖或公开发表。比赛主办方有权对参赛作品进行展示、宣传等相关活动,但知识产权仍归参赛者所有。
十五、联系方式
赛题交流QQ群:1087228412
邮箱:aicomp2026uav@139.com
报名官网:www.aicomp.cn
 2025精彩瞬间
2025精彩瞬间
 大赛回顾
大赛回顾
 关注我们
关注我们